unsignedlonglonggenrand64_int64(void) { //... for (i=0;i<NN-MM;i++) { x = (mt[i]&UM)|(mt[i+1]&LM); mt[i] = mt[i+MM] ^ (x>>1) ^ mag01[(int)(x&1ULL)]; } for (;i<NN-1;i++) { x = (mt[i]&UM)|(mt[i+1]&LM); mt[i] = mt[i+(MM-NN)] ^ (x>>1) ^ mag01[(int)(x&1ULL)]; } //... }
然后是63位生成
1 2 3 4 5
/* generates a random number on [0, 2^63-1]-interval */ longlonggenrand64_int63(void) { return (longlong)(genrand64_int64() >> 1); }
实数的生成
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
/* generates a random number on [0,1]-real-interval */ doublegenrand64_real1(void) { return (genrand64_int64() >> 11) * (1.0/9007199254740991.0); }
/* generates a random number on [0,1)-real-interval */ doublegenrand64_real2(void) { return (genrand64_int64() >> 11) * (1.0/9007199254740992.0); }
/* generates a random number on (0,1)-real-interval */ doublegenrand64_real3(void) { return ((genrand64_int64() >> 12) + 0.5) * (1.0/4503599627370496.0); }
typedefstructredisObject { unsigned type:4; unsigned encoding:4; unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or * LFU data (least significant 8 bits frequency * and most significant 16 bits access time). */ int refcount; void *ptr; } robj;
typedefstructclient { // ... redisDb *db; /* Pointer to currently SELECTed DB. */ // ... } client;
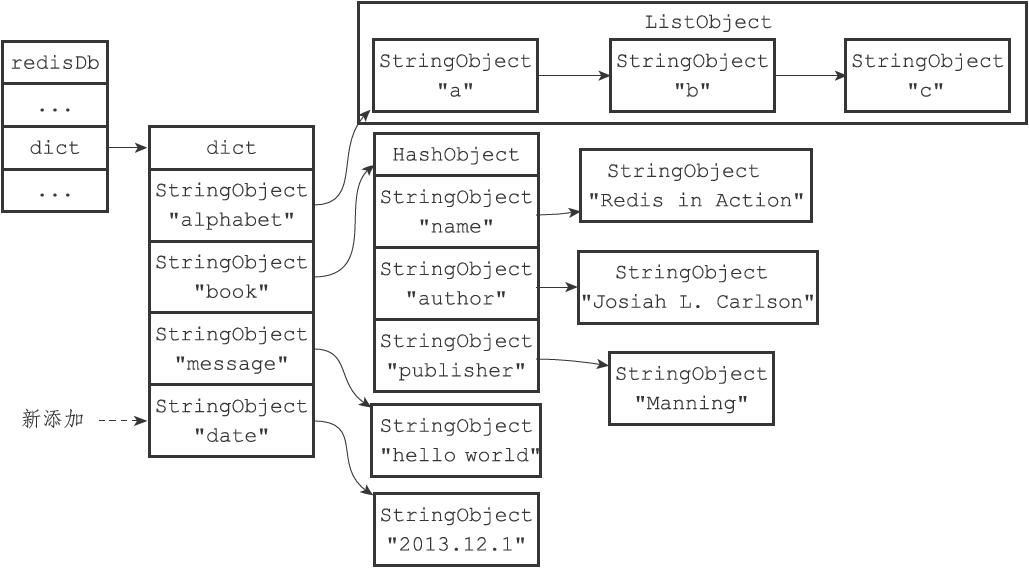
看完服务器和客户端,然后看db
1 2 3 4 5 6 7 8 9 10 11 12 13 14
/* Redis database representation. There are multiple databases identified * by integers from 0 (the default database) up to the max configured * database. The database number is the 'id' field in the structure. */ typedefstructredisDb { dict *dict; /* The keyspace for this DB */ dict *expires; /* Timeout of keys with a timeout set */ dict *blocking_keys; /* Keys with clients waiting for data (BLPOP)*/ dict *ready_keys; /* Blocked keys that received a PUSH */ dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */ int id; /* Database ID */ longlong avg_ttl; /* Average TTL, just for stats */ unsignedlong expires_cursor; /* Cursor of the active expire cycle. */ list *defrag_later; /* List of key names to attempt to defrag one by one, gradually. */ } redisDb;
struct _rio { /* Backend functions. * Since this functions do not tolerate short writes or reads the return * value is simplified to: zero on error, non zero on complete success. */ size_t (*read)(struct _rio *, void *buf, size_t len); size_t (*write)(struct _rio *, constvoid *buf, size_t len); off_t (*tell)(struct _rio *); int (*flush)(struct _rio *); /* The update_cksum method if not NULL is used to compute the checksum of * all the data that was read or written so far. The method should be * designed so that can be called with the current checksum, and the buf * and len fields pointing to the new block of data to add to the checksum * computation. */ void (*update_cksum)(struct _rio *, constvoid *buf, size_t len);
/* The current checksum and flags (see RIO_FLAG_*) */ uint64_t cksum, flags;
/* number of bytes read or written */ size_t processed_bytes;
/* maximum single read or write chunk size */ size_t max_processing_chunk;
/* Backend-specific vars. */ union { /* In-memory buffer target. */ struct { sds ptr; off_t pos; } buffer; /* Stdio file pointer target. */ struct { FILE *fp; off_t buffered; /* Bytes written since last fsync. */ off_t autosync; /* fsync after 'autosync' bytes written. */ } file; /* Connection object (used to read from socket) */ struct { connection *conn; /* Connection */ off_t pos; /* pos in buf that was returned */ sds buf; /* buffered data */ size_t read_limit; /* don't allow to buffer/read more than that */ size_t read_so_far; /* amount of data read from the rio (not buffered) */ } conn; /* FD target (used to write to pipe). */ struct { int fd; /* File descriptor. */ off_t pos; sds buf; } fd; } io; };
/* Flushes any buffer to target device if applicable. Returns 1 on success * and 0 on failures. */ staticintrioBufferFlush(rio *r) { UNUSED(r); return1; /* Nothing to do, our write just appends to the buffer. */ }
/* Returns 1 or 0 for success/failure. */ staticsize_trioBufferRead(rio *r, void *buf, size_t len) { if (sdslen(r->io.buffer.ptr)-r->io.buffer.pos < len) return0; /* not enough buffer to return len bytes. */ memcpy(buf,r->io.buffer.ptr+r->io.buffer.pos,len); r->io.buffer.pos += len; return1; }
/* Returns read/write position in buffer. */ staticoff_trioBufferTell(rio *r) { return r->io.buffer.pos; }
/* Flushes any buffer to target device if applicable. Returns 1 on success * and 0 on failures. */ staticintrioBufferFlush(rio *r) { UNUSED(r); return1; /* Nothing to do, our write just appends to the buffer. */ }
staticconst rio rioBufferIO = { rioBufferRead, rioBufferWrite, rioBufferTell, rioBufferFlush, NULL, /* update_checksum */ 0, /* current checksum */ 0, /* flags */ 0, /* bytes read or written */ 0, /* read/write chunk size */ { { NULL, 0 } } /* union for io-specific vars */ };
if (r->io.file.autosync && r->io.file.buffered >= r->io.file.autosync) { fflush(r->io.file.fp); if (redis_fsync(fileno(r->io.file.fp)) == -1) return0; r->io.file.buffered = 0; } return retval; }
接下来的两个io分别是connection io和 file descriptor io, 前者只实现了从socket中读取数据的接口,后者只实现了向fd中写数据的接口(This target is used to write the RDB file to pipe, when the master just streams the data to the replicas without creating an RDB on-disk image (diskless replication option))。
/* Iterate this DB writing every entry */ while((de = dictNext(di)) != NULL) { sds keystr = dictGetKey(de); robj key, *o = dictGetVal(de); longlong expire;
initStaticStringObject(key,keystr); expire = getExpire(db,&key); if (rdbSaveKeyValuePair(rdb,&key,o,expire) == -1) goto werr;
/* When this RDB is produced as part of an AOF rewrite, move * accumulated diff from parent to child while rewriting in * order to have a smaller final write. */ if (rdbflags & RDBFLAGS_AOF_PREAMBLE && rdb->processed_bytes > processed+AOF_READ_DIFF_INTERVAL_BYTES) { processed = rdb->processed_bytes; aofReadDiffFromParent(); }
/* Update child info every 1 second (approximately). * in order to avoid calling mstime() on each iteration, we will * check the diff every 1024 keys */ if ((key_count++ & 1023) == 0) { longlong now = mstime(); if (now - info_updated_time >= 1000) { sendChildInfo(CHILD_INFO_TYPE_CURRENT_INFO, key_count, pname); info_updated_time = now; } } }
/* If we are storing the replication information on disk, persist * the script cache as well: on successful PSYNC after a restart, we need * to be able to process any EVALSHA inside the replication backlog the * master will send us. */ if (rsi && dictSize(server.lua_scripts)) { di = dictGetIterator(server.lua_scripts); while((de = dictNext(di)) != NULL) { robj *body = dictGetVal(de); if (rdbSaveAuxField(rdb,"lua",3,body->ptr,sdslen(body->ptr)) == -1) goto werr; } dictReleaseIterator(di); di = NULL; /* So that we don't release it again on error. */ }
if (rdbSaveModulesAux(rdb, REDISMODULE_AUX_AFTER_RDB) == -1) goto werr;
/* EOF opcode */ if (rdbSaveType(rdb,RDB_OPCODE_EOF) == -1) goto werr;
/* CRC64 checksum. It will be zero if checksum computation is disabled, the * loading code skips the check in this case. */ cksum = rdb->cksum; memrev64ifbe(&cksum); if (rioWrite(rdb,&cksum,8) == 0) goto werr; return C_OK;
intrdbSave(char *filename, rdbSaveInfo *rsi) { char tmpfile[256]; char cwd[MAXPATHLEN]; /* Current working dir path for error messages. */ FILE *fp = NULL; rio rdb; int error = 0;
snprintf(tmpfile,256,"temp-%d.rdb", (int) getpid()); fp = fopen(tmpfile,"w"); if (!fp) { char *cwdp = getcwd(cwd,MAXPATHLEN); serverLog(LL_WARNING, "Failed opening the RDB file %s (in server root dir %s) " "for saving: %s", filename, cwdp ? cwdp : "unknown", strerror(errno)); return C_ERR; } // ... }
/* Make sure data will not remain on the OS's output buffers */ if (fflush(fp)) goto werr; if (fsync(fileno(fp))) goto werr; if (fclose(fp)) { fp = NULL; goto werr; } fp = NULL; // ... }