

由于计算机内部memery与 processor之间的速度差距过大,导致计算机整体速度降低,memery拖慢了速度。于是人们想出 了一个办法来解决他。缓存Cache诞生了。
Cache相对于Memery来说,速度快了很多,速度快意味着造价高,容量小,这是代价,我们没有那么多钱来用Cache来当作 Memery,于是我们尝试,让他作为Processor与Memery的中介。
为什么要Cache,因为Memery太慢了,用Cache的话,容量问题很显然,Cache很小,没有Memery那么大。但是我们的初衷 是什么,用Cache去代替Memery,但是,Cache这个家伙小啊,我们不可能把一个大的东西放进一个小的盒子里面。 这是缓存 面临的最大问题。
重新思考计算机的运转,指令是一条一条执行的,当计算机运转的时候,CPU关心的不是整个Memery,他只要他的东西,他所需要的 只是局部的信息。于是我们开始思考,既然Cache没有Memery那么大,那我们就构建一个一对多的映射,一个Cache地址,去对应 多个Memery地址,问题似乎解决了,是的Cache就是那样工作的。
一对多的问题不好解决,你怎么知道一对多的时候,对应的是哪一个呢?我们是这样子解决的,把Memery的地址映射 Mx到Cache的地址Cx,这是唯一的,但是Cache是一对多啊,我们假设是一对四,然后我们在Cache的地址所指向的位置添 加一个标记,用来指示他目前对应是哪一个Memery地址,不妨说他目前对应的是第三个Memery。现在问题基本解决了。 例如:
有四个Memery地址Mx1,Mx2,Mx3,Mx4,都映射到了Cx,但是Cx上有一个标记,标记说Cx目前存的值等于Mx3 存的值。这样就完美解决了映射的问题。但是新的问题来了,无法逃避,Cache毕竟没有Memery那么大,我现在 要访问Mx1,结果我找到了Cx,Cx却告诉我他现在存的东西不是Mx1,而是Mx3,怎么办??
没办法,这种情况叫miss,只能从Memery找了,我们是这样做的:把从Memery把Mx1以及他附近的其他东西搬过来 搬到Cache,然后更新Cache的标志。回到刚才的例子,也就是把Mx1以及他附近的其他信息的东西搬到了Cx上 然后改掉Cx的标记,说Cx现在不是Mx3了,他现在与Mx1一起了。
如此复杂的操作,真的回使得计算机变快吗?是的,平均性能上提高了,因为Cache和Memery速度差异巨大。不过杨老师曾指出一个 反例,他说,你要是有个恐怖分子,不用我们的Cache,当Cx与Mx1一致的时候你要用Mx2,当Cx变得根Mx2相同了,你 又要用Mx1,那岂不是凉凉?好像确实是这样子的。
为什么说是平均性能的提高呢?有两点,memery使用的时间局部性和空间局部性,当你使用了一个Memery的地址 后,你在不久的将来可能还会使用他 ,你也有肯能使用他附近的其他信息。所以我们把和他相关的东西一股脑都放进 Cache就可以了,但是放多少呢?这个问题,先辈们已经通过统计得出来结论。我们不必关心。
Cache的基本实际实现
之前我们谈到的只是口糊,具体实现的时候,不是一个地址对应一个地址,而是一块对应一块(block), 我们曾谈到,空间局部性,所以说这里不要一个地址对应一个地址的玩了。我们引入block。也就是说 我们把地址Mx1_begin 到Mx1_end这一整块的地址映射到Cx_begin到Cx_end , 然后放一个标记就可以了, 这样的优点很多,比如说省掉了很多标记的记录。。。等等的
Cache的地址分为三大块,tag,index,和offset
offset指的是一种偏移量,我们之前说过,Cache里面分了很多个block,每一个block都是一个整体,所以 当我们找到了正确的当block当时候,offset用来指向block里面的详细地址。显然,block里面有多少种地址 offset就有多少种值。举个例子,当block是64B的时候,他一共有2^6个byte,我们计算机寻址所关心的只是 哪一个byte,(一般而言,四个byte为一个words)所以我们的offset需要有6个bit,才能恰好指向这2^6个 byte。于是在这种情况下offset为6位
index指向我们要找的哪一个block,见杨老师的图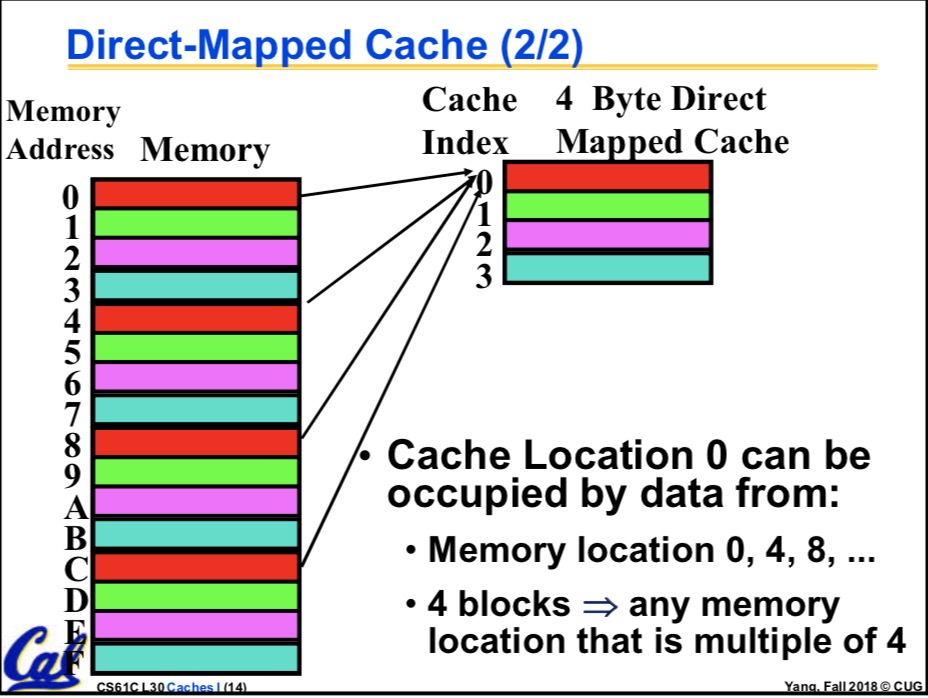
很明显,如果在上述条件下我们的Cache一共有64KB的话,那我们就有 64KB/6B=2^10个block,于是index就是10位的了,可是有一些Cache,特别的有趣,它允许多对多。这就很 头疼了,不过这确实是个好办法。有一定的优点。 多对多是个什么情况呢?类似于这样,有Cx1 Cx2,Mx1,Mx2,Mx3,Mx4,他们很乱,四个Mx都可能映射到 Cx1,也都可能映射到Cx2,注意对比之前的一对多:有Cx,Mx1,Mx2,Mx3,Mx4,四个Mx都可能映射到Cx 多对多多优点的话,不好说,其实是我不知道。这种多对多的骚操作,实现起来更复杂了,他叫n-way set-assoc. 中文名n路集相关。很shit,很神奇。下面是二路集相关(还是杨老师的).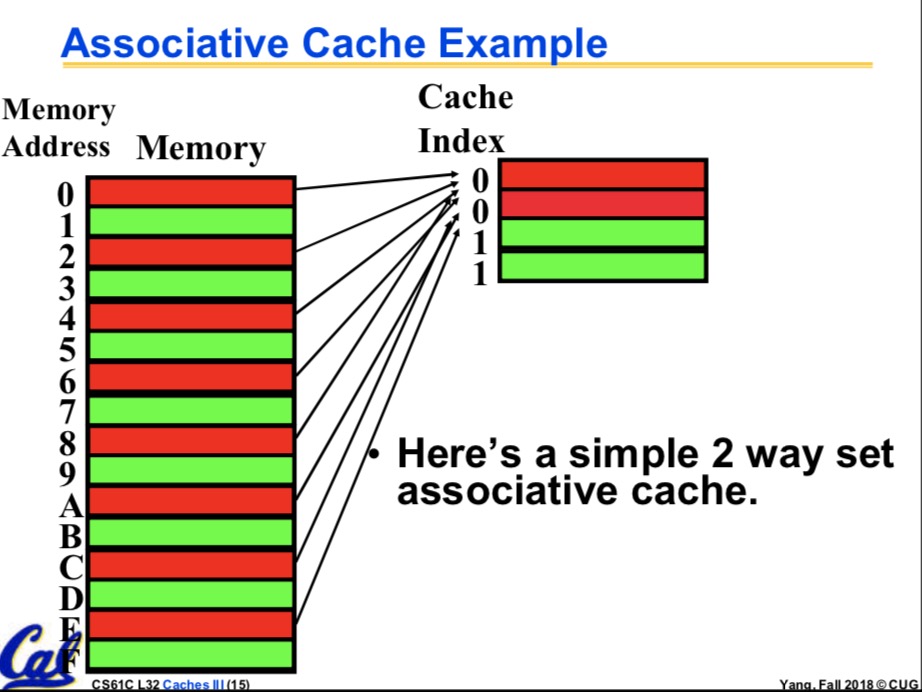
在n路及相关的情况下,index又叫做set,这是他的新名字,这个时候他指向一堆block,换句话说,一堆block共用 一个index。于是,如果刚刚的64KBCache是二路集相关的话,他的index是9位,因为一个index可以指向两个 block。
至于tag,我不是很清楚了。应对考试的话,他的位数用PPA(Physical Page Address )减去index和offset就得到了。
最后剩下的一个是Data Cache entry 他的大小等于Valid bit, Dirty bit, Cache tag + ?? Bytes of Data, 有这些一起组成。Valid bit 一般是一位,他的作用是用来指示这个block是否有用,为什么会没有用呢 我们想到,程序总有启动的时候,当程序刚刚启动的时候,block是无效的,它里面的数据存在,但是 数据却不一定和Memery保持一致。这个问题无法避免,但是可以通过Valid bit解决。Dirty bit是一种懒惰 标记,一般的树形结构,例如线段树,spaly,以及各种可持久化数据结构里面都用这种东西。他用来表明 一种懒惰性,因为Memery慢,因为Cache是用来代替Memery的,当我们读取数据的时候,没有他的用途 单当我们更新数据的时候,我们一定要立即更新Memery吗,不是的,我们可以只更新Cache的block,等 到miss发生的时候,在把它们一起写入Memery即可,所以他叫脏位。是一位。Cache tag就是我们之前说的 标记,用来防止一对多的情况下的那个标记,他等于前面我们算出来的tag的大小。最后一个是Bytes of Data 他恰好等于block的大小,例如64KB的那个Cache,他的大小位64KB=64*8bits=512bits,于是总大小为 1+1+21+512=535bits


- 本文作者: fightinggg
- 本文链接: http://fightinggg.github.io/yilia/yilia/PQVZ80.html
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!