

HTTP权威指南

第一章: HTTP概述
媒体类型
因特上有数千种不同的数据类型,HTTP仔细地给每种要通过Web传输的对象都打上了名为MIME类型( MIME type)的数据格式标签。最初设计MIME( Multipurpose Internet Mail Extension,多用途因特网邮件扩展)是为了解决在不同的电子邮件系统之间搬移报文时存在的问题。MIME在电子邮件系统中工作得非常好,因此HTTP也采纳了它,用它来描述并标记多媒体内容。
Page: 6

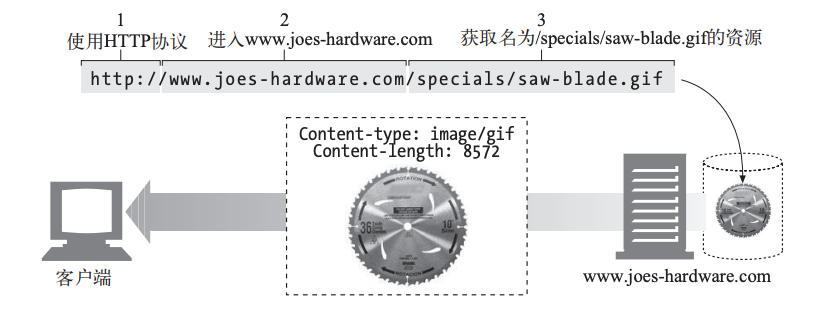
URI
服务器资源名被称为统一资源标识符( Uniform Resource Identifier,URI)。
Page: 7
URI分为两种,URL(统一资源定位符)和URN(统一资源名)
下面是一个URL例子
URN是作为特定内容的唯一名称使用的,与目前的资源所在地无关。使用这些与位置无关的URN,就可以将资源四处搬移。通过URN,还可以用同一个名字通过多种网络访问协议来访问资源。例如我们可以访问RFC 2141
1 | urn:ietf:rfc:2141 |
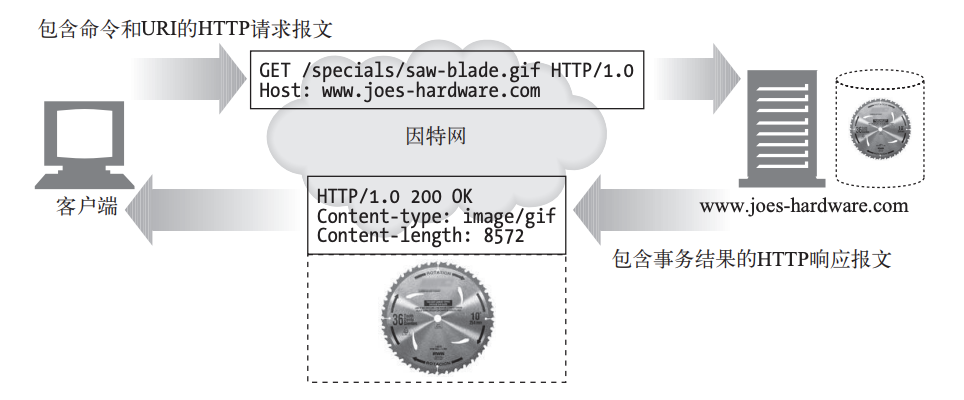
事务
一个HTTP事务由一条(从客户端发往服务器的)请求命令和一个(从服务器发回客户端的)响应结果组成。
Page: 7
方法
包含 GET, PUT, DELETE, POST, HEAD
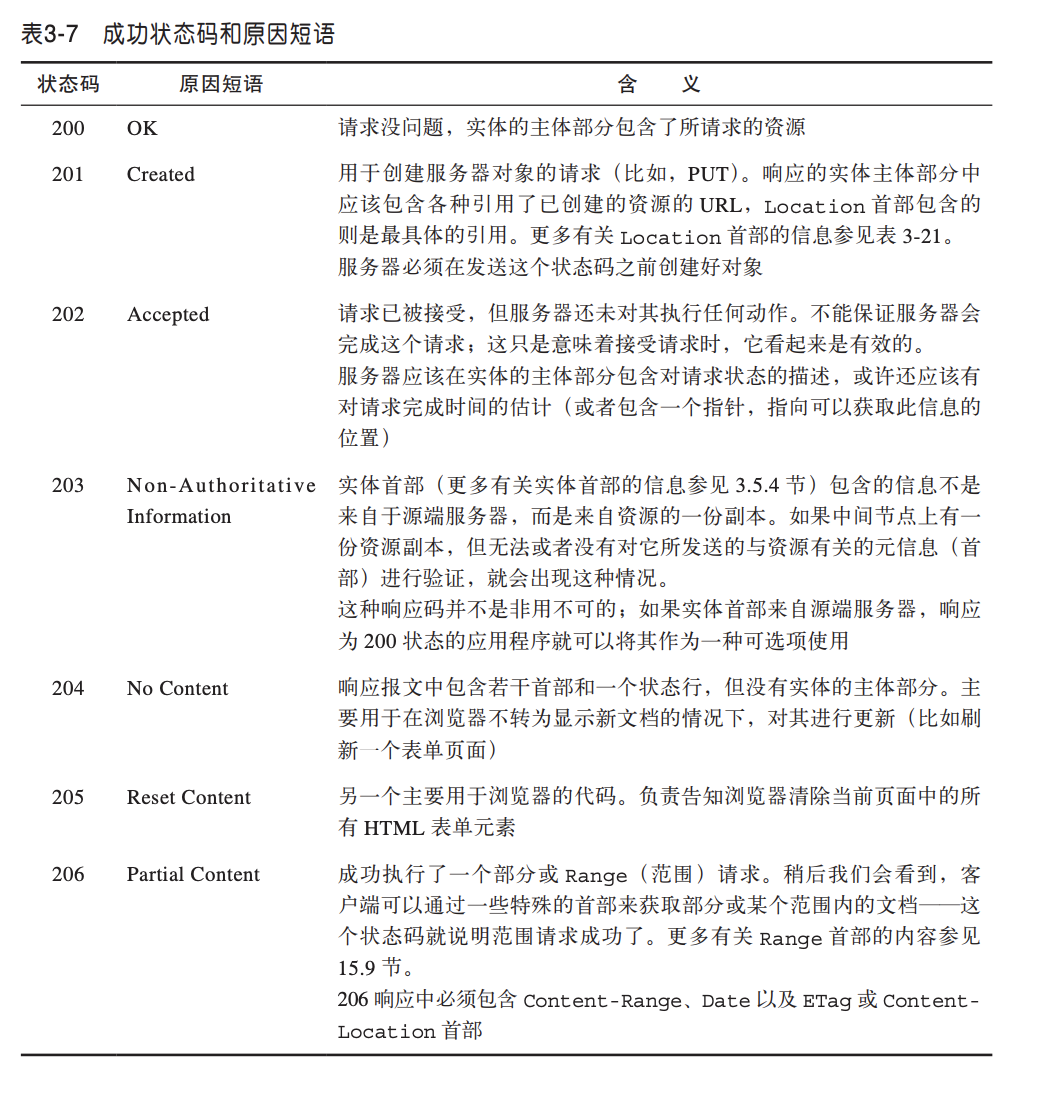
状态码
每条HTP响应报文返回时都会携帯一个状态码。状态码是一个三位数字的代码告知客户端请求是否成功,或者是否需要采取其他动作。
Page: 8
报文
HTTP报文是由一行一行的简单字符串组成的。HTTP报文都是纯文本,不是二进制代码,所以人们可以很方便地对其进行读写。
有些程序员会抱怨HTTP的语法解析太困难了,这项工作需要很多技巧,而且很容易出错,尤其是在设计高速软件的时候更是如此。二进制格式或更严格的文本格式可能更容易处理,但大多数HTTP程序员都很欣赏HTTP的可扩展性以及可调试性
Page: 9
HTTP报文包括以下三个部分
- 起始行:报文的第一行就是起始行,在请求报文中用来说明要做些什么,在响应报文中说明出现了什么情况
- 首部字段:起始行后面有零个或多个首部字段。毎个首部字段都包含一个名字一个值,为了便于解析,两者之间用冒号(:)来分隔。首部以一个空行结束,添加一个首部字段和添加新行一样简单。
- 主体:空行之后就是可选的报文主体了,其中包含了所有类型的数据。请求主体中包括了要发送给Web服务器的数据;响应主体中装教了要返回给客户端的数据。起始行和首部都是文本形式且都是结构化的,而主体则不同,主体中可以包含任意的二进制数据(比如图片、视频、音轨、软件程序)。当然,主体中也可以包含文本。
想看看HTTP报文吗?下面就是一个HTTP报文。学会指令CURL
1 | [root@VM-4-4-centos ~]# curl -v www.baidu.com |
> 即为我们发送的信息
< 即为我们收到的信息
Telnet伪造
我们来使用telnet伪造一个HTTP请求,按照下面的方案进行输入
1 | [root@VM-4-4-centos ~]# telnet www.baidu.com 80 |
然后你就能得到一堆百度的返回

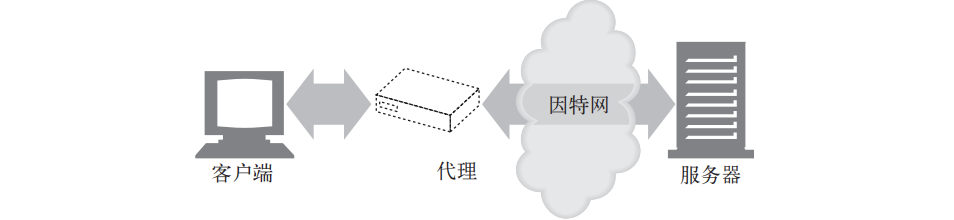
代理是位于服务器和客户端之间的中间体
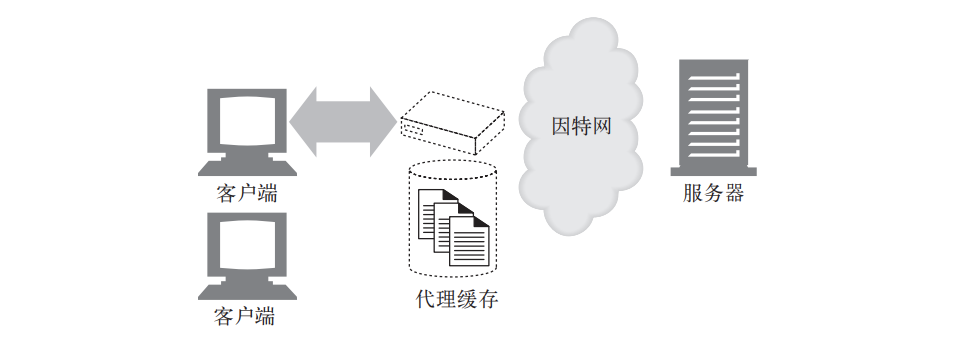
缓存
网关一般用于协议转换
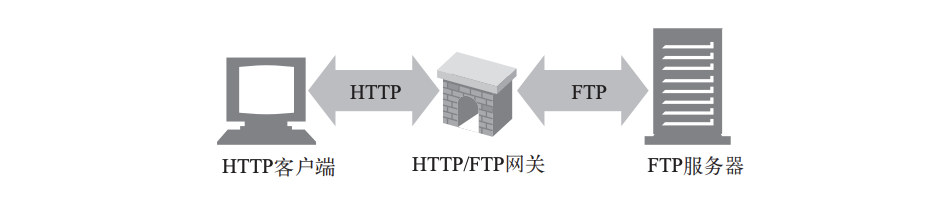
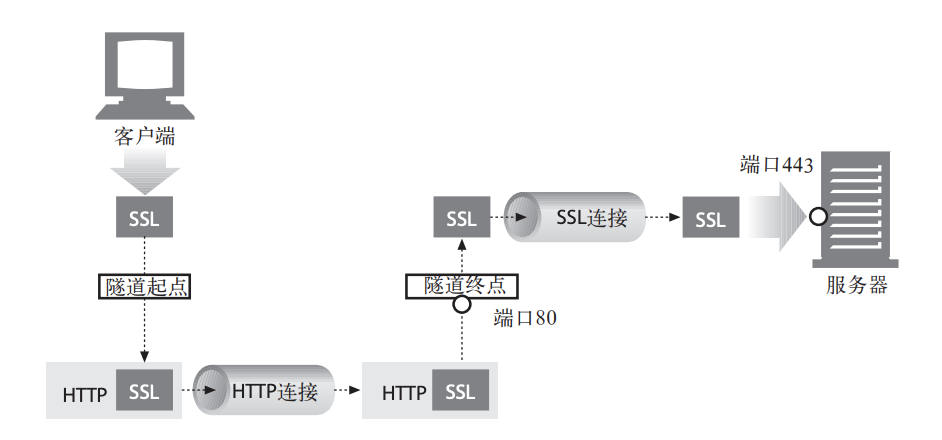
隧道,这是一个对SSL报文封包的例子
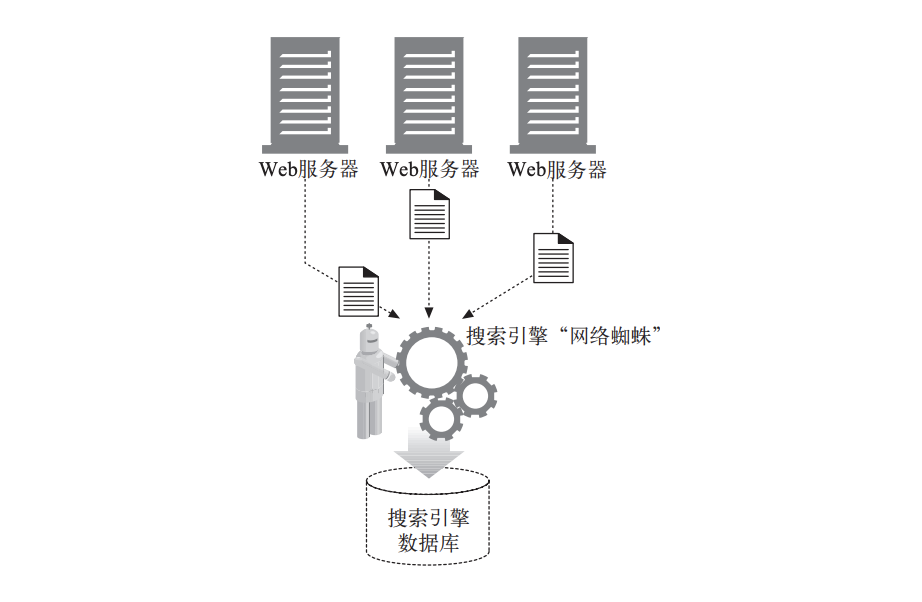
Agent代理,Web浏览器是最常见的代理,除此以外还有网络蜘蛛、web机器人等
第二章 URL与资源

方案
即使用什么协议,必须用字母开头,并用第一个:把URL分割开。
用户名和密码
ftp就是一个需要账号密码的协议,比如
1 | ftp://ftp.prep.ai.mit.edu/pub/gnu |
第一个例子会默认账号: anonymous, 默认密码: xxx(各浏览器不一致)
第二个例子指定了账号anonymous
第三个例子同时指定了账号和密码,用:分割
主机和端口
http://www.baidu.com:80/path/to?hello=world
端口是80
路径
http://www.baidu.com:80/path/to?hello=world
路径是/path/to
参数
参数被字符;分割
ftp://prep.ai.mit.edu/pub/gnu;type=d
参数是type,值为d
http://www.joes-hardware.com/hammers;sale=false/index.html;graphics=true
每一个路径都可以有参数
查询字符串
http://www.baidu.com:80/path/to?hello=world
参数是hello=world
片段
https://fightinggg.github.io/QQZ90O.html#片段
这个片段直接指向了这块区域
第三章 HTTP报文
安全方法
GET和HEAD就是安全的方法,他们不用产生动作
GET
通常是请求服务器发送某个资源
HEAD
HEAD方法与GET方法的行为很类似,但服务器在响应中只返回首部。不会返回实体的主体部分。这就允许客户端在未获取实际资源的情况下,对资源的首部进行检査。使用HEAD,可以:
在不获取资源的情况下了解资源的情况(比如,判断其类型)
通过査看响应中的状态码,看看某个对象是否存在
通过查看首部,测试资源是否被修改了
服务器开发者必须确保返回的首部与GET请求所返回的首部完全相同。遵循 HTTP/.1规范,就必须实现HEAD方法。
Page: 57
PUT
PUT是向服务器写入某资源
POST
POST向服务器发送数据
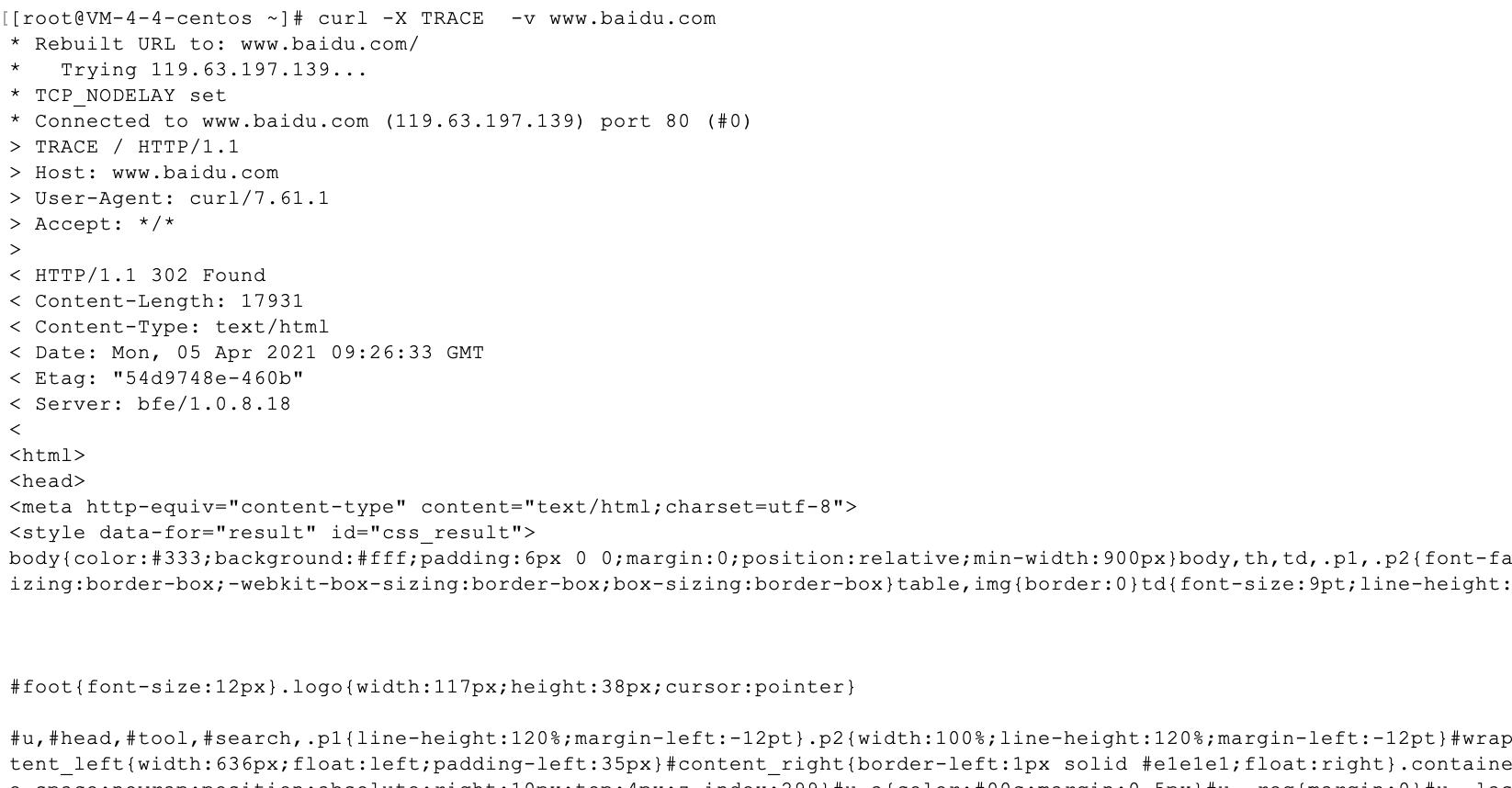
TRACE
这是一个诊断请求
TRACE请求会在目的服务器端发起一个“环回”诊断。行程最后一站的服务器会弹回一条 TRACE响应,并在响应主体中携带它收到的原始请求报文。这样客户端就可以査看在所有中间HTTP应用程序组成的请求/响应链上,原始报文是否,以及如何被毁坏或修改过.
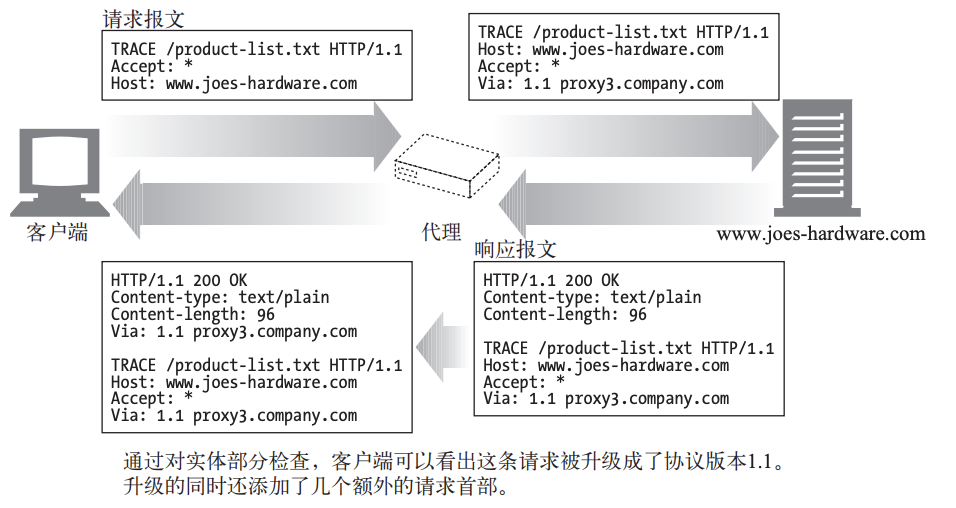
这是一个TRACE的例子,看来百度不太给劲啊。
github也是这样
1 | [root@VM-4-4-centos ~]# curl -X TRACE -v www.github.com |
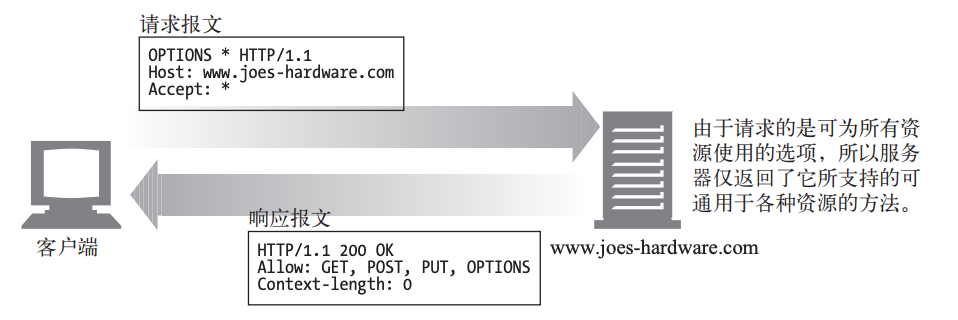
OPTIONS
OPTIONS 方法请求 Web 服务器告知其支持的各种功能。可以询问服务器通常支持 哪些方法,或者对某些特殊资源支持哪些方法。(有些服务器可能只支持对一些特殊 类型的对象使用特定的操作)。
百度还是一如即往
1 | [root@VM-4-4-centos ~]# telnet www.baidu.com 80 |
1 | [root@VM-4-4-centos ~]# telnet www.github.com 80 |
DELETE
删除某资源
状态码


- 本文作者: fightinggg
- 本文链接: http://fightinggg.github.io/yilia/yilia/QQZ90O.html
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!