题意
给你一个集合s
让你把这个集合划分为两个集合
在集合A中若x存在则a-x也存在
在集合B中若x存在则b-x也存在
数据范围
|s|<1e5
a<1e9
b<1e9
注意
集合中不包含相同的数
题解
使用并查集维护,
容易证明若x和a-x存在,则他们必定在同一个集合中
x和b-x同理
代码
1 |
|

相信不屈不挠的努力,相信战胜死亡的年轻

给你一个集合s
让你把这个集合划分为两个集合
在集合A中若x存在则a-x也存在
在集合B中若x存在则b-x也存在
|s|<1e5
a<1e9
b<1e9
集合中不包含相同的数
使用并查集维护,
容易证明若x和a-x存在,则他们必定在同一个集合中
x和b-x同理
1 |
|
多项式在计算机中一般以数组方式储存,假设有一个多项式$f(x)$,并且$x^i$前面的系数为$a_i$,那么显然我们恰好可以用一个数组$a$来描述这个多项式, 多项式的系数$a_i$恰好存在数组$a$的第$i$项$a[i]$
在一般的多项式中,如果模数允许,乘法采取ntt来做,因为速度较快,多项式乘法是整个多项式体系的基石,他的常数如果太大,将影响到后面的所 有的多项式操作
我们需要设置多项式最大长度,模数,原根,多项式最大长度的log,以及关键点reduce函数,传入一个-mod到mod之间的数x,返回x%mod,他比取模更快,然后是快速幂,在往后是复数i在模意义下的值,2i在模意义下的逆元,以及后面的逆元数组和他的初始化函数
1 | const int maxn=100005<<2,mod = 998244353,g=3;// const 能明显加速代码 |
蝴蝶变化必须预处理出来,否则太慢,最前面的是蝴蝶变换r[i][j]数组, 之后是ntt单位根wn数组和他的逆元数组。接着是ntt的数组的预处理函数以及ntt函数本体
1 | int allr[maxn<<1],*r[30],ntt_wn[30],ntt_revwn[30]; // 特别详细,没啥其他可说的 |
为了后期代码可观性良好,以及少写一些奇怪的代码,poly_cpy(int*a,int n,int*b,int exn)提供了多项式拷贝等操作,即将一个多项式拷贝到另外一个多项式,必须保证exn>=n ,即先将a[0…n-1]拷贝到b[0…n-1] 然后把b数组多余的部分清零。这里如果ab为同一个数组,就不必进行拷贝了。
1 | void poly_cpy(int*a,int n,int *b,int exn){// |
为了防止常数问题,这里依旧采取最简单的方式,不让数组发生过多的拷贝,我们只实现a*=b这一个步骤,不实现c=a*b这种,很套路的乘法,先变为点指表示法 然后变为系数表示法即可
1 | void poly_mul(int*a,int na,int*b,int nb){ |
若两个多项式$f$和$g$,求出$f*g$然后让系数对mod取模,多项式忽略高于$x^k$次的项后等于1,则$f$和$g$互逆
这个地方很难以理解,因为有两个取模,所以会让很多初学者感到困惑,只要注意两个模是不同的,一个是系数对mod取模,另一个是多项式整体对$x^k$取模,即可
整个算法采取牛顿迭代法来完成,很容易被数学归纳法证明,$f(x)*g(x)===1(x^k,mod)$,当k等于1的时候,非常好得出结果,显然那时候g(x)至少需要 1项,即常数项,大于常数项的部分无效的,这个很容易证明,这一项等于$f(x)$的常数项的逆元。然后我们来根据$f(x)*g(x)===1(x^k,mod)$推出$f(x)g(x)===1(x^2k,mod)$ 的结果,以下是推导过程,显然$g(x)=g(x)(2-f(x)*g(x))$,只要自己注意一下项数的变化即可,然后我们倍增即可得出答案时间复杂度$T(n)=T(n/2)+nlg(n)$ 根据主定理$T(n)=O(nlgn)$ img
img
1 | void poly_inv(int*a,int n,int*b){ // // %(x^n) b(2-ab) |
除法会有剩余,所以有两个返回值。
对于一个n-1次多项式f(x) 定义F(x)=x^nf(1/x) 则有以下推导 img 余数直接ntt暴力即可
img 余数直接ntt暴力即可
1 | void poly_div(int*a,int na,int*b,int nb,int*c,int*d){ |
 img
img
于是求导、求逆、乘、积分即可完成
1 | void poly_der(int*a,int n,int*b){ // 微分求导 |
大佬已将讲的很清楚了,用泰勒展开求的 img
img
1 | void poly_exp(int*a,int n,int*b){//a[exn(n+n-1)] // 保证f(0)=0 b(1-ln(b)+f), |
递归边界改为二次剩余即可 img
img
1 | void poly_sqrt(int*a,int n,int*b){//a[exn(n+n-1)] //保证a[0]=1, (b+a/b)/2 比上面那个好一些 |
先取对数,然后乘,然后取exp
1 | void poly_pow(int *a,int n,int k,int *b){//a[exn(n+n-1)] // a^k not quick pow but quicker |

1 | void poly_sin(int*a,int n,int*b){//a[exn(n+n-1)]// 保证a[0]=0 -> c[0]=0 -> 可以exp |
。。。。。。没啥可说的,存粹的套路
1 |
|
1 | // a^x === b x=lg(a,b) |
对于一个离散函数$f(x), x\in Z^+$ , 如果$\forall \gcd(a,b)=1$都有$f(a\cdot b)=f(a)\cdot f(b)$, 则称函数$f(x)$为积性函数。
对于一个离散函数$f(x), x\in Z^+$ , 如果$\forall a,b\in Z^+$都有$f(a\cdot b)=f(a)\cdot f(b)$, 则称函数$f(x)$为完全积性函数。
我们根据积性函数的定义,其实只要我们计算出了所有素数的幂的函数值,则任何其他$f(x)$都可以快速获取。
对此笔者准备了一个模版,我们只需要修改其中的56到63行即可
$\phi(n)$就是小于等于n,且与n互质的数的个数。
1 | //O(lgn)适用于少求 |
1 | //求单个值 |
1 |
|
很早就想写这个了,觉得好厉害,结果分析停留在理论上,其实时间复杂度贼高
1 |
|
输出了斐波拉契700位,数据还行,就是太慢了。

1 | struct Tarjan:Graph{//强连通分量缩点 |
1 | struct Graph{ |
边双联通
1 | struct Graph{ |
1 | struct Graph{ |
程序跑起来都是跟地址相关的,可以试想,如果多个程序一起跑,难道不相互影响吗?又或者说 为什么我们写代码,从不去关心我们的程序在哪里运行?大家都用一个Memory,为什么没有相互破坏?好神奇!!
为了让多个程序在同一台计算机上更好的运行,而不发生相互破坏性影响,虚拟内存的概念被提了出来,从此多个程序都有了独立的地址空间。
虚拟内存,是与物理内存相对应的,可以设想,我们程序a运行起来,写地址Mx1,程序b运行起来 也写Mx1,结果是,他们没有相互影响,为什么?因为这个地址Mx1是虚拟内存,是假的,程序a的mx1 和程序b的mx1不是同一个地址,程序a写Mx1,结果写到哪去了呢?我们不知道,这件事是操作系统 完成的,他把程序a的Mx1映射到了一个地方,又把程序b的Mx1映射到了另一个地方,这两个程序就能 独立的跑起来了。
解决上述问题的方法很简单,是有一个叫做页表的东西来完成的。
为了更好的解决这个问题,我们将内存分页,就成了多个page,假设一个page有16KB,那么page里面的 地址就有16KB=2^14B,个地址,我们需要用14bits来表示这个地址,所以,基于这种page模式 地址的低14位就是page offset,页偏移量,其他的高位叫做page number,在虚拟内存里面 叫做Virutal page number,在物理内存里面叫做Physical page number ,注意物理内存和虚拟内存 的page offset是一样的。于是我们一个page一个page的映射,一次映射就是一整页。页内部保持地址 一致,地址映射只是page number变化。
我们之前说过,操作系统进行了一次映射,这个映射是怎么完成的呢?于是叶表出来了,有一张表 记录了所有虚拟内存地址页号(vpn)到物理内存地址页号的(ppn)的所有信息,显然为了高效性 这里我们使用数组来完成,在c++里面如果有一个数组a[4]={1,2,0,3};那么就有a[0]=1,a[1]=2,a[2]=0, a[3]=3;ok 映射完成了!!O(1)映射,高性能。但是还是有一个问题。这个数组可能回究极大大大大。 设想一个64GB的物理内存,以及1024GB的虚拟内存,页大小16KB,那么会导致36位的 physical address 40位的virtual address 以及14位的page offset,然后我们发现physical page number 达到了22位,virtual page number 达到了26位,我们来算一下这个数组有多大,26位的元素,2^26*22?bit,大概是150MB左右 这么大,缓存也放不下呀,只能放内存里面,可是这这东西读取频率是究极高的,放内存里面读写太慢了。
于是我们思考能不能把一部分经常要用到放到Cache里面?能啊!!为什么不能?为了让叶表用的更加得劲, 我们还专门给你弄一个Cache,重新取名位TLB。哈哈。TLB和普通Cache一样,page offset和 TLB index TLB tag和Cache的一摸一样,计算方法一摸一样,此处不再多言。
这也是一样的,只是多一个Access Control (一般 2 bits),也就多两位来着。Cache懂了这里很简单。
我们用数学方式来重新定义计算机里面的运算,因为内存是有限的,所以我们在计算机当中 存储数据的时候,这些数据都是有范围的数,所以所有的运算都是建立在模数上的,例如加法成了 模加。a+b成了(a+b)%mod。
为了让减法跑的更快,我们把减法丢掉了,于是这个世界只有加法了。减法成了加一个负数。 负数又是怎么定义的呢?如果x=-1,我们可以这样来存储(0-1+mod)%mod=mod-1 于是我们把负数也映射到了新的正数上。
由于模加也满足加法的交换率结合律等等优良性质。很明显,对于负数-x和-y我们存的是mod-x 和mod-y,于是经历模加(-x+-y)%mod=(mod-x+mod-y)%mod这显然是正确的。
由于计算机内部memery与 processor之间的速度差距过大,导致计算机整体速度降低,memery拖慢了速度。于是人们想出 了一个办法来解决他。缓存Cache诞生了。
Cache相对于Memery来说,速度快了很多,速度快意味着造价高,容量小,这是代价,我们没有那么多钱来用Cache来当作 Memery,于是我们尝试,让他作为Processor与Memery的中介。
为什么要Cache,因为Memery太慢了,用Cache的话,容量问题很显然,Cache很小,没有Memery那么大。但是我们的初衷 是什么,用Cache去代替Memery,但是,Cache这个家伙小啊,我们不可能把一个大的东西放进一个小的盒子里面。 这是缓存 面临的最大问题。
重新思考计算机的运转,指令是一条一条执行的,当计算机运转的时候,CPU关心的不是整个Memery,他只要他的东西,他所需要的 只是局部的信息。于是我们开始思考,既然Cache没有Memery那么大,那我们就构建一个一对多的映射,一个Cache地址,去对应 多个Memery地址,问题似乎解决了,是的Cache就是那样工作的。
一对多的问题不好解决,你怎么知道一对多的时候,对应的是哪一个呢?我们是这样子解决的,把Memery的地址映射 Mx到Cache的地址Cx,这是唯一的,但是Cache是一对多啊,我们假设是一对四,然后我们在Cache的地址所指向的位置添 加一个标记,用来指示他目前对应是哪一个Memery地址,不妨说他目前对应的是第三个Memery。现在问题基本解决了。 例如:
有四个Memery地址Mx1,Mx2,Mx3,Mx4,都映射到了Cx,但是Cx上有一个标记,标记说Cx目前存的值等于Mx3 存的值。这样就完美解决了映射的问题。但是新的问题来了,无法逃避,Cache毕竟没有Memery那么大,我现在 要访问Mx1,结果我找到了Cx,Cx却告诉我他现在存的东西不是Mx1,而是Mx3,怎么办??
没办法,这种情况叫miss,只能从Memery找了,我们是这样做的:把从Memery把Mx1以及他附近的其他东西搬过来 搬到Cache,然后更新Cache的标志。回到刚才的例子,也就是把Mx1以及他附近的其他信息的东西搬到了Cx上 然后改掉Cx的标记,说Cx现在不是Mx3了,他现在与Mx1一起了。
如此复杂的操作,真的回使得计算机变快吗?是的,平均性能上提高了,因为Cache和Memery速度差异巨大。不过杨老师曾指出一个 反例,他说,你要是有个恐怖分子,不用我们的Cache,当Cx与Mx1一致的时候你要用Mx2,当Cx变得根Mx2相同了,你 又要用Mx1,那岂不是凉凉?好像确实是这样子的。
为什么说是平均性能的提高呢?有两点,memery使用的时间局部性和空间局部性,当你使用了一个Memery的地址 后,你在不久的将来可能还会使用他 ,你也有肯能使用他附近的其他信息。所以我们把和他相关的东西一股脑都放进 Cache就可以了,但是放多少呢?这个问题,先辈们已经通过统计得出来结论。我们不必关心。
之前我们谈到的只是口糊,具体实现的时候,不是一个地址对应一个地址,而是一块对应一块(block), 我们曾谈到,空间局部性,所以说这里不要一个地址对应一个地址的玩了。我们引入block。也就是说 我们把地址Mx1_begin 到Mx1_end这一整块的地址映射到Cx_begin到Cx_end , 然后放一个标记就可以了, 这样的优点很多,比如说省掉了很多标记的记录。。。等等的
Cache的地址分为三大块,tag,index,和offset
offset指的是一种偏移量,我们之前说过,Cache里面分了很多个block,每一个block都是一个整体,所以 当我们找到了正确的当block当时候,offset用来指向block里面的详细地址。显然,block里面有多少种地址 offset就有多少种值。举个例子,当block是64B的时候,他一共有2^6个byte,我们计算机寻址所关心的只是 哪一个byte,(一般而言,四个byte为一个words)所以我们的offset需要有6个bit,才能恰好指向这2^6个 byte。于是在这种情况下offset为6位
index指向我们要找的哪一个block,见杨老师的图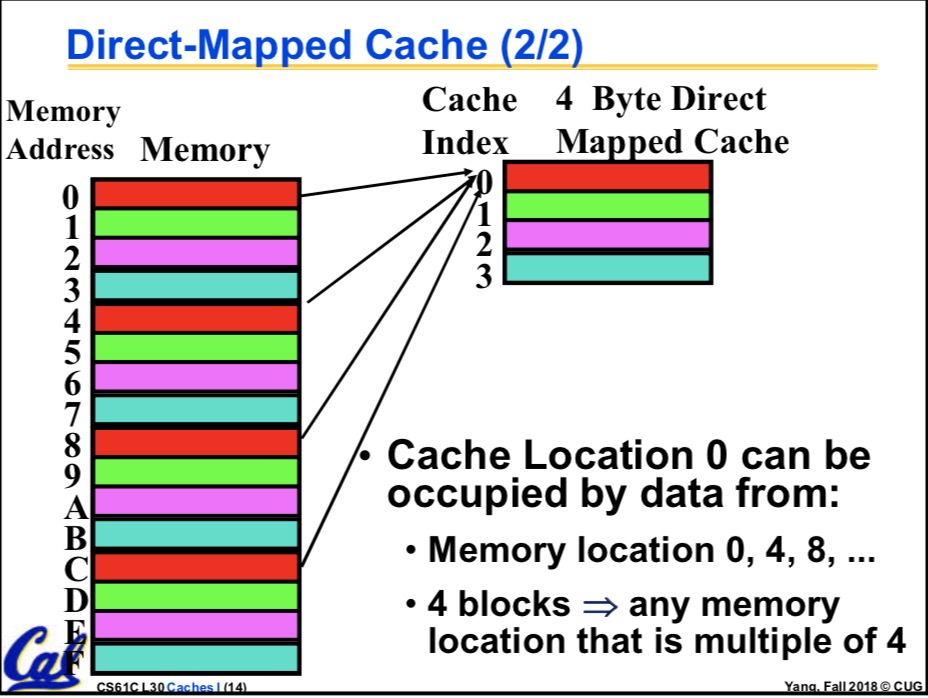
很明显,如果在上述条件下我们的Cache一共有64KB的话,那我们就有 64KB/6B=2^10个block,于是index就是10位的了,可是有一些Cache,特别的有趣,它允许多对多。这就很 头疼了,不过这确实是个好办法。有一定的优点。 多对多是个什么情况呢?类似于这样,有Cx1 Cx2,Mx1,Mx2,Mx3,Mx4,他们很乱,四个Mx都可能映射到 Cx1,也都可能映射到Cx2,注意对比之前的一对多:有Cx,Mx1,Mx2,Mx3,Mx4,四个Mx都可能映射到Cx 多对多多优点的话,不好说,其实是我不知道。这种多对多的骚操作,实现起来更复杂了,他叫n-way set-assoc. 中文名n路集相关。很shit,很神奇。下面是二路集相关(还是杨老师的).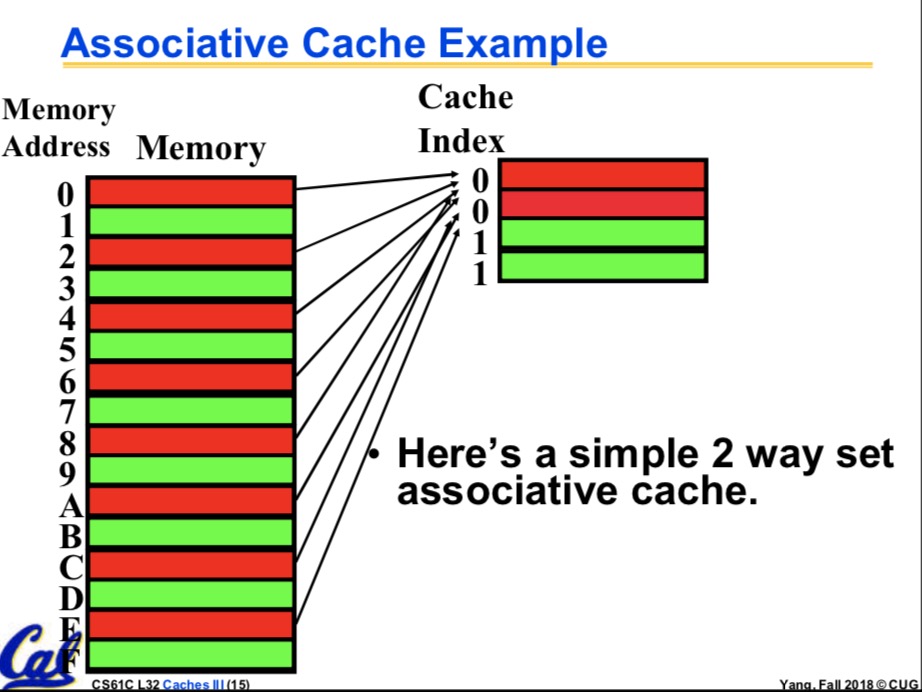
在n路及相关的情况下,index又叫做set,这是他的新名字,这个时候他指向一堆block,换句话说,一堆block共用 一个index。于是,如果刚刚的64KBCache是二路集相关的话,他的index是9位,因为一个index可以指向两个 block。
至于tag,我不是很清楚了。应对考试的话,他的位数用PPA(Physical Page Address )减去index和offset就得到了。
最后剩下的一个是Data Cache entry 他的大小等于Valid bit, Dirty bit, Cache tag + ?? Bytes of Data, 有这些一起组成。Valid bit 一般是一位,他的作用是用来指示这个block是否有用,为什么会没有用呢 我们想到,程序总有启动的时候,当程序刚刚启动的时候,block是无效的,它里面的数据存在,但是 数据却不一定和Memery保持一致。这个问题无法避免,但是可以通过Valid bit解决。Dirty bit是一种懒惰 标记,一般的树形结构,例如线段树,spaly,以及各种可持久化数据结构里面都用这种东西。他用来表明 一种懒惰性,因为Memery慢,因为Cache是用来代替Memery的,当我们读取数据的时候,没有他的用途 单当我们更新数据的时候,我们一定要立即更新Memery吗,不是的,我们可以只更新Cache的block,等 到miss发生的时候,在把它们一起写入Memery即可,所以他叫脏位。是一位。Cache tag就是我们之前说的 标记,用来防止一对多的情况下的那个标记,他等于前面我们算出来的tag的大小。最后一个是Bytes of Data 他恰好等于block的大小,例如64KB的那个Cache,他的大小位64KB=64*8bits=512bits,于是总大小为 1+1+21+512=535bits
缺失模块。
1、请确保node版本大于6.2
2、在博客根目录(注意不是yilia-plus根目录)执行以下命令:
npm i hexo-generator-json-content --save
3、在根目录_config.yml里添加配置:
jsonContent:
meta: false
pages: false
posts:
title: true
date: true
path: true
text: false
raw: false
content: false
slug: false
updated: false
comments: false
link: false
permalink: false
excerpt: false
categories: false
tags: true